RAID (Redundant array of Independent Disks) and RAID Levels
The general idea behind
RAID is to employ a group of hard drives together with some form of
duplication, either to increase reliability or to speed up operations,
( or sometimes both. )
RAID originally
stood for Redundant Array of Inexpensive Disks, and was
designed to use a bunch of cheap small disks in place of one or two larger more
expensive ones.
Today RAID systems
employ large possibly expensive disks as their components, switching the
definition to Independent disks. (Redundant Array
of Independent Disks.)
1. Improvement of
Reliability via Redundancy
If the same data was
copied onto multiple disks, then the data would not be lost unless both (
or all ) copies of the data were damaged simultaneously, which is a much lower
probability than for a single disk going bad. More specifically, the second
disk would have to go bad before the first disk was repaired, which brings
the Mean Time To Repair into play. For example if two disks
were involved, each with a MTTF of 100,000 hours and a MTTR of 10 hours, then
the Mean Time to Data Loss would be 500 * 10^6 hours, or
57,000 years!
This is the basic idea
behind disk mirroring, in which a system contains identical data on
two or more disks.
2. Improvement
in Performance via Parallelism
There is also a
performance benefit to mirroring, particularly with respect to reads. Since
every block of data is duplicated on multiple disks, read operations can be
satisfied from any available copy, and multiple disks can be reading different
data blocks simultaneously in parallel. (Writes could possibly be sped up as
well through careful scheduling algorithms, but it would be complicated in
practice.
Another way of
improving disk access time is with striping, which basically means
spreading data out across multiple disks that can be accessed simultaneously.
o
With bit-level striping the
bits of each byte are striped across multiple disks. For example if 8 disks
were involved, then each 8-bit byte would be read in parallel by 8 heads on
separate disks. A single disk read would access 8 * 512 bytes = 4K worth of
data in the time normally required to read 512 bytes. Similarly if 4 disks were
involved, then two bits of each byte could be stored on each disk, for 2K worth
of disk access per read or write operation.
o
Block-level striping spreads
a filesystem across multiple disks on a block-by-block basis, so if block N
were located on disk 0, then block N + 1 would be on disk 1, and so on. This is
particularly useful when filesystems are accessed in clusters of
physical blocks. Other striping possibilities exist, with block-level striping
being the most common.
RAID Levels
Mirroring provides
reliability but is expensive; Striping improves performance, but does not
improve reliability. Accordingly there are a number of different schemes that
combine the principals of mirroring and striping in different ways, in order to
balance reliability versus performance versus cost. These are described by
different RAID levels, as follows:
1. Raid Level 0
- This level includes striping only, with no mirroring.

2. Raid Level 1
- This level includes mirroring only, no striping.

3. Raid Level 2
- This level stores error-correcting codes on additional disks,
allowing for any damaged data to be reconstructed by subtraction from the
remaining undamaged data. Note that this scheme requires only three extra disks
to protect 4 disks worth of data, as opposed to full mirroring. ( The number of
disks required is a function of the error-correcting algorithms, and the means
by which the particular bad bit(s) is(are) identified. )

4. Raid Level 3
- This level is similar to level 2, except that it takes advantage
of the fact that each disk is still doing its own error-detection, so that when
an error occurs, there is no question about which disk in the array has the bad
data. As a result a single parity bit is all that is needed to recover the lost
data from an array of disks. Level 3 also includes striping, which improves
performance. The downside with the parity approach is that every disk must take
part in every disk access, and the parity bits must be constantly calculated
and checked, reducing performance. Hardware-level parity calculations and NVRAM
cache can help with both of those issues. In practice level 3 is greatly
preferred over level 2.

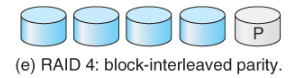
5. Raid Level 4
- This level is similar to level 3, employing block-level striping
instead of bit-level striping. The benefits are that multiple blocks can be
read independently, and changes to a block only require writing two blocks (
data and parity ) rather than involving all disks. Note that new disks can be
added seamlessly to the system provided they are initialized to all zeros, as
this does not affect the parity results.
6. Raid Level 5
- This level is similar to level 4, except the parity blocks are
distributed over all disks, thereby more evenly balancing the load on the
system. For any given block on the disk(s), one of the disks will hold the
parity information for that block and the other N-1 disks will hold the data.
Note that the same disk cannot hold both data and parity for the same block, as
both would be lost in the event of a disk crash.

7. Raid Level 6
- This level extends raid level 5 by storing multiple bits of
error-recovery codes, ( such as the Reed-Solomon
codes ), for each bit position of data,
rather than a single parity bit. In the example shown below 2 bits of ECC are
stored for every 4 bits of data, allowing data recovery in the face of up to
two simultaneous disk failures. Note that this still involves only 50% increase
in storage needs, as opposed to 100% for simple mirroring which could only
tolerate a single disk failure.

There are also two RAID
levels which combine RAID levels 0 and 1 ( striping and mirroring ) in
different combinations, designed to provide both performance and reliability at
the expense of increased cost.
·
RAID level 0 + 1 disks
are first striped, and then the striped disks mirrored to another set. This
level generally provides better performance than RAID level 5.
·
RAID level 1 + 0 mirrors
disks in pairs, and then stripes the mirrored pairs. The storage capacity,
performance, etc. are all the same, but there is an advantage to this approach
in the event of multiple disk failures

In
diagram (a) below, the 8 disks have been divided into two sets of four, each of
which is striped, and then one stripe set is used to mirror the other set.
o
If a single disk fails, it wipes out the
entire stripe set, but the system can keep on functioning using the remaining
set.
o
However if a second disk from the other
stripe set now fails, then the entire system is lost, as a result of two disk
failures.
In diagram (b), the
same 8 disks are divided into four sets of two, each of which is mirrored, and
then the file system is striped across the four sets of mirrored disks.
o
If a single disk fails, then that mirror
set is reduced to a single disk, but the system rolls on, and the other three
mirror sets continue mirroring.
o
Now if a second disk fails, ( that is
not the mirror of the already failed disk ), then another one of the mirror
sets is reduced to a single disk, but the system can continue without data
loss.
o
In fact the second arrangement could
handle as many as four simultaneously failed disks, as long as no two of them
were from the same mirror pair.
Selecting a RAID Level
- Trade-offs
in selecting the optimal RAID level for a particular application include
cost, volume of data, need for reliability, need for performance, and
rebuild time, the latter of which can affect the likelihood that a second
disk will fail while the first failed disk is being rebuilt.
- Other
decisions include how many disks are involved in a RAID set and how many
disks to protect with a single parity bit. More disks in the set increases
performance but increases cost. Protecting more disks per parity bit saves
cost, but increases the likelihood that a second disk will fail before the
first bad disk is repaired.
No comments:
Post a Comment